MQ整合
# 消息队列
消息队列也被称之为MQ,消息队列并不是什么高端的技术,只是微服务架构中的,解决应用的解耦、异步消息、流量削峰、消息分发的一个中间件;什么是消息队列呢?消息应该都理解是什么,队列呢,队列是大家在银行办理业务时人多了需要排队是一个概念,这也就不难理解消息队列了(可以理解成在排队的消息,并且里面有多个窗口)。

# 消息队列的组成
# Broker
消息服务器,作为server提供消息核心服务
# Producer
消息生产者,业务的发起方,负责生产消息传输给broker,
# Consumer
消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理
# Topic
主题,发布订阅模式下的消息统一汇集地,不同生产者向topic发送消息,由MQ服务器分发到不同的订阅者,实现消息的 广播
# Queue
队列,PTP模式下,特定生产者向特定queue发送消息,消费者订阅特定的queue完成指定消息的接收
# Message
消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输
# 应用解耦
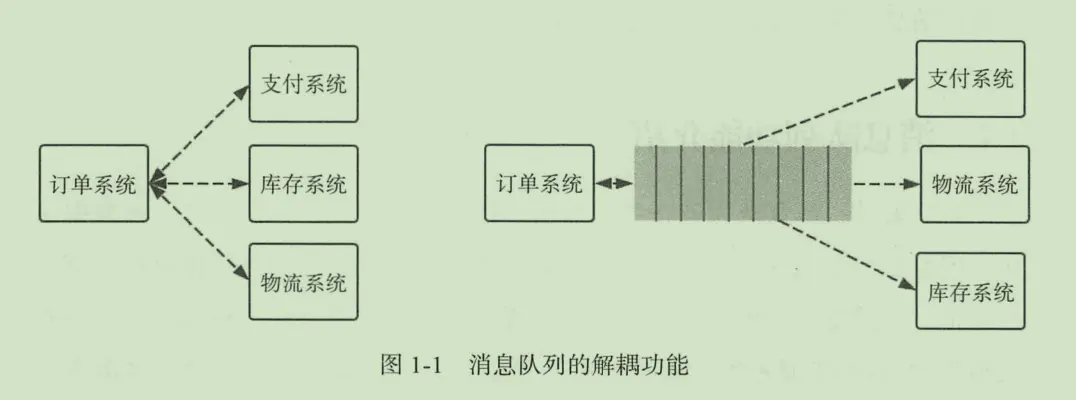
以微服务中的订单系统,支付系统、库存系统为例,三个代表每个系统模块的微服务,当 用户下完订单后,需要告诉支付系统有用户已下单-->需要付款、需要减少库存等操作;如果耦合调用的话,当其中任何一个环节出现了问题,可能需要几分钟才能修复,都会订单失败,会导致服务在这段未修复的时间段中,服务不能用,可能会导致一部分用户的丢失或投诉等相关问题;如果使用消息队列降解耦后,订单系统只需要把下的订单发送到消息队列中,当其中某个环节在此出现上述的问题时,只需要先把消息存放在消息队列中,等系统修复完成之后,重新监听系统中的消息对消息进行消费操作即可。
# 流量削峰
微服务中常见的订单系统为例,假如订单系统每秒钟只能处理10W条订单量,在正常的情况下是没有问题的,突然有一天每秒来了20W的订单需要处理,但是这时已经超出系统能承受的范围了,一般有时候会把订单限制在10W条之内,超出10W的直接做阻断的操作;这种虽然也可以解决,但是对用户可能就不是很友好了。消息队列中的流量削峰的概念可以解决以上出现的问题,用消息队列作为缓冲,当用户操作的时候先把用户的订单信息存放在消息队列中,当流量到达处理的顶峰的时候,可以使用消息堆积的方式,只处理到达顶峰之前的订单,另一部分等处理完成之后再进行处理。
# MQ保证消息的不丢失
# RabbitMQ
1、选择MQ提供的事物功能,生产者在发布消息之前开启一个事物,然后进行消息的发送,mq接受到消息后,会自动提交事物,如果mq没有收到成功的消息,会异常报错,进行错误捕获,消息重新发送。
提示
缺点:效率低下、因为开启了mq的事物,会变成阻塞状态,等待处理结果结束后返回,再进行下一步的处理。
channel.txSelect();//开启事物
try{
//发送消息
}catch(Exection e){
channel.txRollback();//回滚事物
//重新提交
}
2、在生产者哪里设置开启了confirm模式之后,每次写的消息都会分配一个唯一的id,然后如何写入了rabbitmq之中,rabbitmq会给你回传一个ack消息,告诉你这个消息发送OK了;如果rabbitmq没能处理这个消息,会回调你一个nack接口,告诉你这个消息失败了,你可以进行重试。而且你可以结合这个机制知道自己在内存里维护每个消息的id,如果超过一定时间还没接收到这个消息的回调,那么你可以进行重发。
//开启confirm
channel.confirm();
//发送成功回调
public void ack(String messageId){
}
// 发送失败回调
public void nack(String messageId){
//重发该消息
}
# 消费者弄丢数据解决方案
使用rabbitmq提供的ack机制,首先关闭rabbitmq的自动ack,然后每次在确保处理完这个消息之后,在代码里手动调用ack。这样就可以避免消息还没有处理完就ack。
# kafka
# 消费端丢失
1、消费端消息丢失是通过,关闭自定提交offset,在自己处理完毕之后手动提交offset,这样就可以保证消费端的不会把消息弄丢
# 自身消息丢失
1、kafka自身消息丢失问题,可以同过设置参数来保证消息的不丢失: ① 给topic设置 replication.factor参数:这个值必须大于1,表示每个partition必须至少有两个副本; ②在kafka服务端设置min.isync.replicas参数:这个值必须大于1,表示 要求一个leader至少感知到有至少一个follower在跟自己保持联系正常同步数据,这样才能保证leader挂了之后还有一个follower。 ③在生产者端设置acks=all:表示 要求每条每条数据,必须是写入所有replica副本之后,才能认为是写入成功了 ④在生产者端设置retries=MAX(很大的一个值,表示无限重试):表示 这个是要求一旦写入事变,就无限重试。
# 生产消息丢失
如果按照上面设置了ack=all,则一定不会丢失数据,要求是,你的leader接收到消息,所有的follower都同步到了消息之后,才认为本次写成功了。如果没满足这个条件,生产者会自动不断的重试,重试无限次。
# MQ之间的对比
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|---|---|---|---|---|
| API完备性 | 高 | 高 | 高 | 高 |
| 多语言支持 | 支持,Java优先 | 语言无关 | 只支持Java | 支持,Java优先 |
| 单机吞吐量 | 万级 | 万级 | 万级 | 十万级 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | |
| 可用性 | 高 | (主从) | 高(主从) | 非常高(分布式) |
| 消息丢失 | 低 | 低 | 理论上不会丢失 | 理论上不会丢失 |